Lane line detection using deep learning is an advanced and interesting project. UNet is a popular architecture for image segmentation, making it suitable for this task. Grad-CAM (Gradient-weighted Class Activation Mapping) can help visualize which parts of the image are contributing to the predictions. Unet structure and encode decode helps the process.
Two-step approaches consist of two main phases: feature extraction and post-processing.
The one below is a blog that I refered for undestandingthe process. There's a few scattered about OpenCv on this site too.
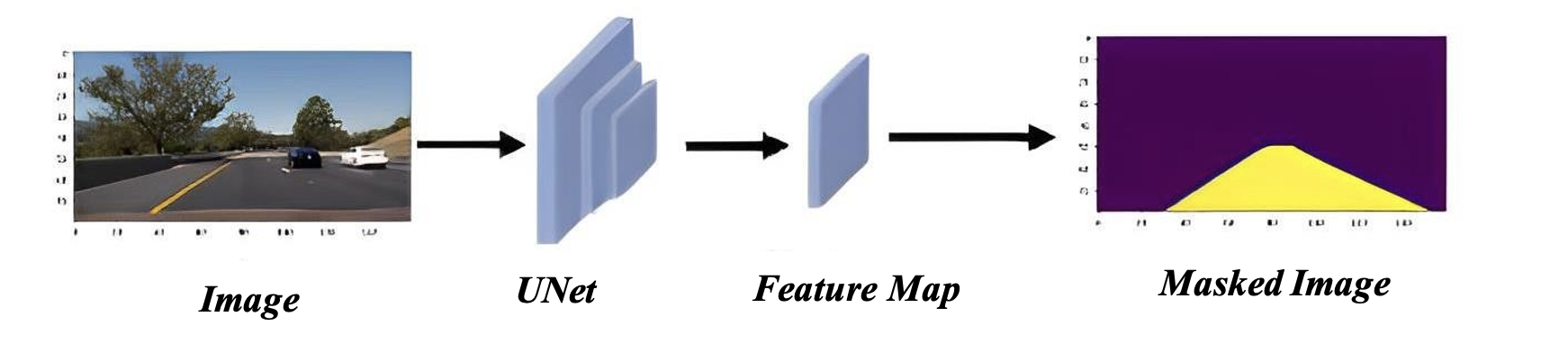
This is the Flow!!
This section imports the necessary libraries for the rest of the code. NumPy is used for numerical computations in Python, pickle is used for serializing and deserializing Python objects, scikit-learn is used for machine learning tasks, Keras is used for building neural networks, and cv2 and matplotlib are used for image manipulation and visualization.
This code shows the third image from the train_img aarray using the function from Matplotlib & creat_model
that creates a lane detection model using the Sequential() function from Keras.
input_shape = X_train.shape[1:]
model = create_model(input_shape, pool_size)the imshow() function from Matplotlib is used to display the images in a 7x3 grid of subplots.
Let's break down a layout together. The subplots() function takes x and y coordinates to position the to convert the 2D array of subplots to a 1D array that can be iterated over with zip() & predict() method, and the predicted output is obtained.
model.compile optimizer='Adam,"loss='mean_squared_error'
history= model .fit_generator(datagen.flow( X_train, y_train=batch_size ="70" height="50" fill="blue"
steps_per_epoch=len (X_train)60/ batch_size
epochs=epochs, verbose=1,validation_data =(X_val,y_val ))
model.trainable=False
💡 Encoder-decoder architectures can be adapted to various tasks by changing the input and output layers.
For exampledecoder can reduce the computational load
Cool, so here's our output Mask.

Model Archietecture permalink
The architecture effectively omits extraneous information while concentrating on the important features for lane detection bycombining the encoded information from the bottleneck with the up-sampling of the decoderReal-TimeLane detection This makes it easier to segregateLines from road.
batch_size= 128
epoches=10
pool_size =(2,2)
input_shape=X_train.shape [1:]
model=create_model(input_shape pool_size)
datagen= ImageDataGenerator(channle_shift_range= "0.2")
datagen
.fit (X_train)
model .compile(optimizer= 'Adam'loss='mean_squared_error' ) href="https://place-puppy.com/300x300"
model. save("landataset .h5)
from keras.models importload_model
model=load_model('/content/drive/MyDrive/lane detection/lanedetect.h5')
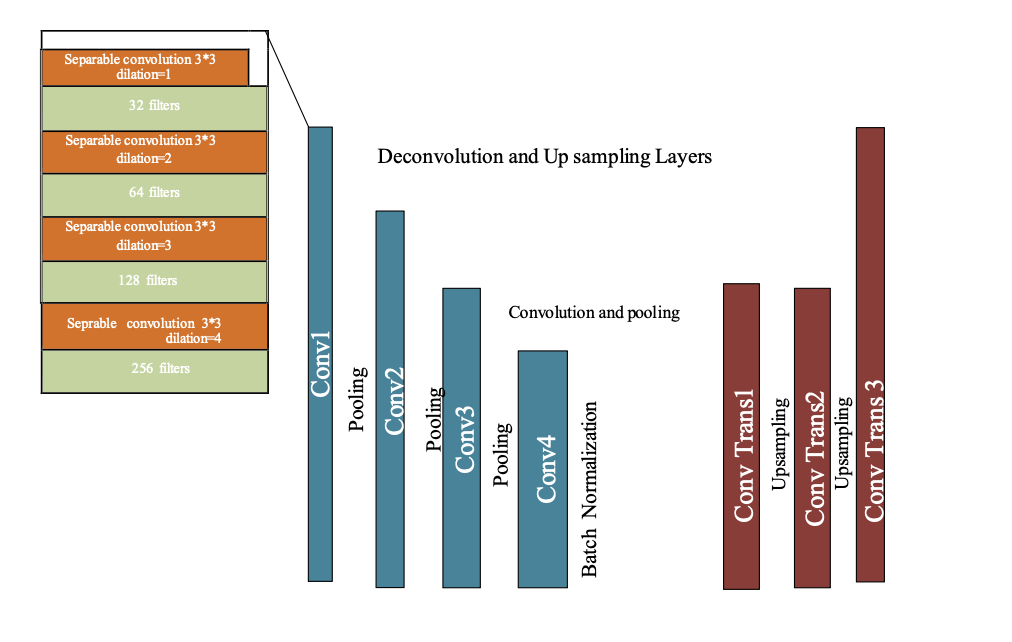
The encoder component of the model is in charge of extracting features from the input picture. This is accomplished in the code by using a sequence of convolutional layers.
The idea is for pixel-level classification. This is a great article from medium if you want to dig into it a bit more.
This is the value we need.
plt .plot(history.history(['loss'])
plot .plot(xMidYMid slicehistory .history[val_loss' ]
plt.show()
.show() This code plots the training and validation loss curves over the epochs training The history object returned by the
method earlier contains the loss fit_generator() which are accessed history.historyattributes.
The plot allows the user to visually inspect the performance of the model during training, and can be used to diagnose issues such as overfitting or underfitting - another awesome thing.
Here's an example of the starting i did.
import matplotlib. pyplot as plt
import numPy as np
plt .imshow (np.array(train_img[2]))
plt.imshow ((np.array(labels[2]).reshape(80,160))