Project Overview
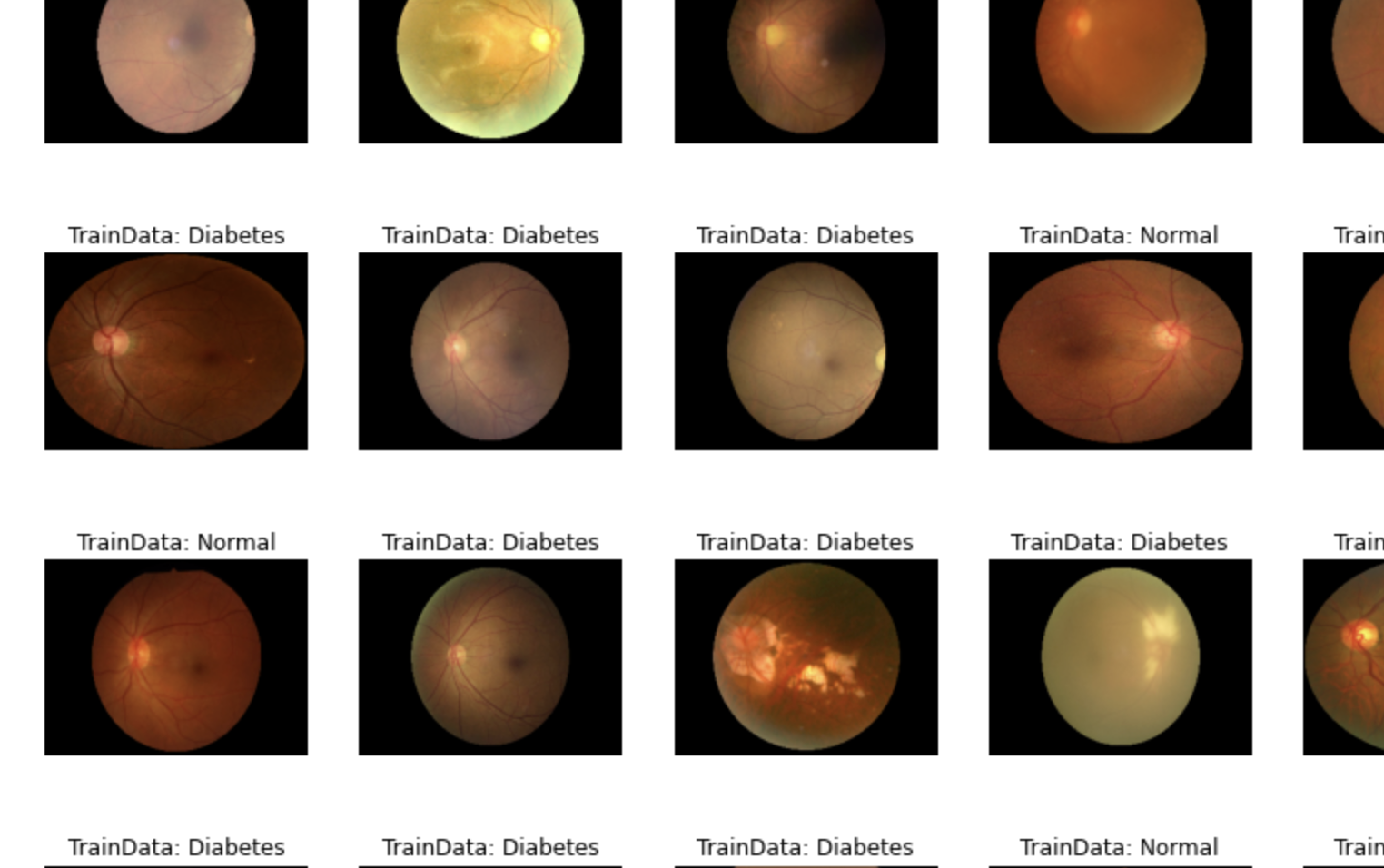
This project aims to classify diabetes based on retina images, leveraging deep learning models to automate the process. The classification is performed using two retinal datasets: Cataract Dataset and Ocular Disease Recognition Dataset (ODIR). These datasets contain various images that can be used to train models to identify diabetic retinopathy or other eye-related diseases indicative of diabetes.
This project aims to detect cataracts from fundus images using deep learning. Cataracts are one of the leading causes of blindness, and early detection is critical for preventing irreversible vision loss. Traditional detection methods involve manual examination of images, which can be time-consuming and prone to human error. This project leverages Convolutional Neural Networks (CNNs) to automatically classify eye images as Normal or Cataract, assisting healthcare professionals in quick and accurate diagnosis.
The aim of this project is to build deep learning models to classify diabetic retinopathy (diabetes-related eye diseases) in retina images, utilizing two public datasets: the Cataract Dataset and the Ocular Disease Recognition Dataset (ODIR-5K). By employing deep learning techniques such as Convolutional Neural Networks (CNN) and transfer learning models like EfficientNet and InceptionV3, the goal is to predict the presence of diabetes based on retina scans
The Data Set Link: ODIR-5K
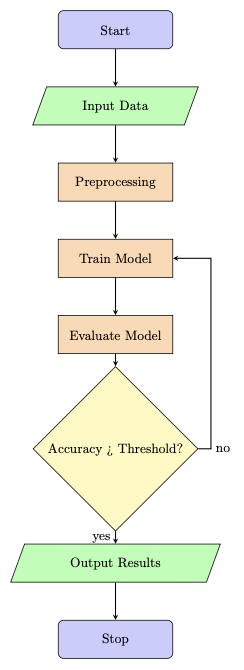
This is the Flow!!
Image Loading: Load retina images from the datasets using paths specified in metadata files (such as .xlsx).
Label Mapping: Map images to labels (0 for non-diabetic, 1 for diabetic retinopathy) based on diagnostic keywords from the metadata.
Data Balancing: Since the datasets are imbalanced (more diabetic images than non-diabetic), apply downsampling to balance the number of images in each class.
Data Augmentation: To increase the diversity of the training set, apply techniques like rotation, flipping, and scaling.
Custom CNN Model:Create a custom Convolutional Neural Network (CNN) with layers like Conv2D, MaxPooling2D, Flatten, and Dense.-
EfficientNetB0 Model:Implement transfer learning by utilizing a pre-trained EfficientNetB0 model as the base. -
EfficientNetB4 Model:Similar to EfficientNetB0 but with a more complex model (larger and deeper), fine-tune the model for better performance. -
InceptionV3 Model:Use a pre-trained InceptionV3 model for transfer learning, freezing the base layers and training a custom classifier on top of it. -
EffUNetB0 Model:Implement a U-Net architecture for segmentation tasks (e.g., to segment retina images and classify areas affected by diabetic retinopathy). EfficientNet is used as the encoder to extract features.
that creates a lane detection model using the Sequential() function from Keras.
model = Sequential()
model.add(LSTM(256,input_shape=(100, 1), return_sequences=True))
model.add(Dropout((0.3))#dropout regularisation
model.add(LSTM(512,, return_sequences=True))
model.add(Dropout((0.3))#dropout regularisation
model.add(LSTM((256))#Third LSTM Layer
model.add(Dense((256))#Fully Connected layer
model.add(Dropout((0.3))#dropout
model.add(Dense((326))#Final Output Layer
model.add(Activation(("softmax"))#Activation
model.compile(loss='categorical_crossentropy',optimizer='rmsprop')Softmax Activation: After the final dense layer, a softmax activation function is applied to the output, which is typical for classification tasks. It converts the raw output scores into probabilities (for each note or category).
Loss Function: The model uses categorical_crossentropy which is appropriate for multi-class classification (e.g., predicting the next note in a music sequence).rmspropis used for training the model, which is a good choice for training RNN-based models (like LSTM).
model.compile optimizer='Adam,"loss='mean_squared_error'
history= model .fit_generator(datagen.flow( X_train, y_train=batch_size ="70" height="50" fill="blue"
steps_per_epoch=len (X_train)60/ batch_size
epochs=epochs, verbose=1,validation_data =(X_val,y_val ))
model.trainable=False
💡 Use a categorical cross-entropy loss function for multi-class classification or binary cross-entropy for binary classification.
Flow of Work permalink
Data Collection:Describe how the data was collected or sourced.
Preprocessing: Explain how the sequences were extracted, how the notes (or values) were encoded as integers, and how the dataset was split into training and validation sets.
def gaussian_kernel (kernel_size= 3):
h = gaussian( kernel_size, kernel_size / 3).
h = np.dot(h, h.transpose())
h /= np.sum(h )
gaussian(kernel_size, sigma): Generates a 1D Gaussian kernel. If you don't specify a sigma value, it is defaulted to kernel_size / 3 as a reasonable starting point.
np.outer(h, h): Converts the 1D Gaussian kernel into a 2D kernel by performing an outer product of the 1D kernel with itself. This creates a 2D Gaussian filter.This is a great article
from medium if you want to dig into it a bit more.
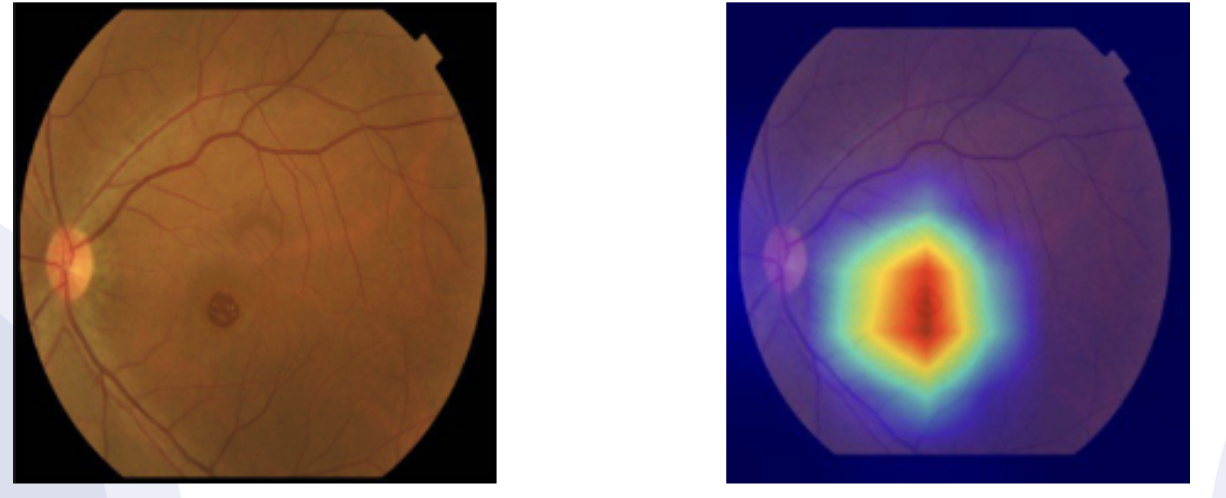
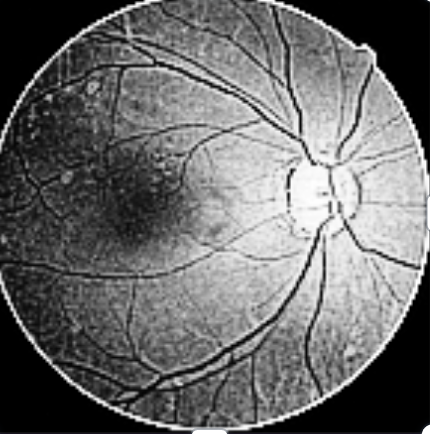
FEvaluate each model’s performance on the validation set using metrics such as accuracy, precision, recall, F1-score, and AUC-ROC. Use a confusion matrix to get insights into classification accuracy across different classes (diabetic and non-diabetic). Visualize the results using Seaborn for heatmaps and confusion matrices.
num_classes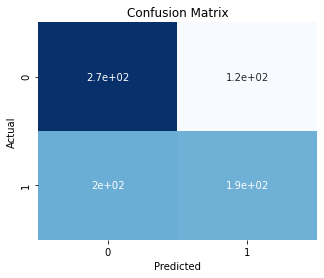
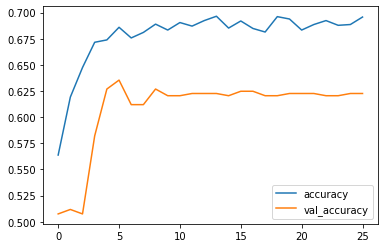
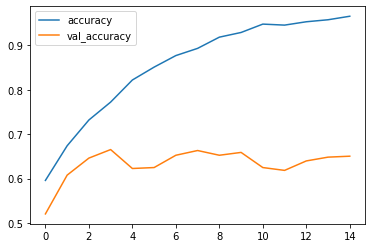
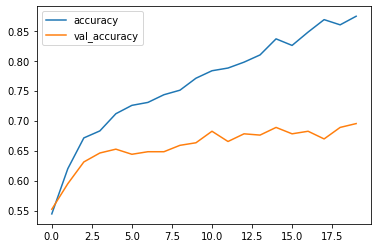 expectation hello
expectation hello