The Music Generation with RNN project involves creating a model that generates music sequences using Recurrent Neural Networks (RNNs), specifically Long Short-Term Memory (LSTM) networks. The music data is converted into a sequence of musical notes, with each note represented as an integer. The model learns patterns from these sequences. The LSTM network is used because of its ability to handle sequential data and learn long-term dependencies in time-series data like music.
The model consists of multiple LSTM layers with dropout layers to avoid overfitting and improve generalization.
The one below is a Github code link that I made for undestandingthe process. There's a few scattered about RNN on this site too.
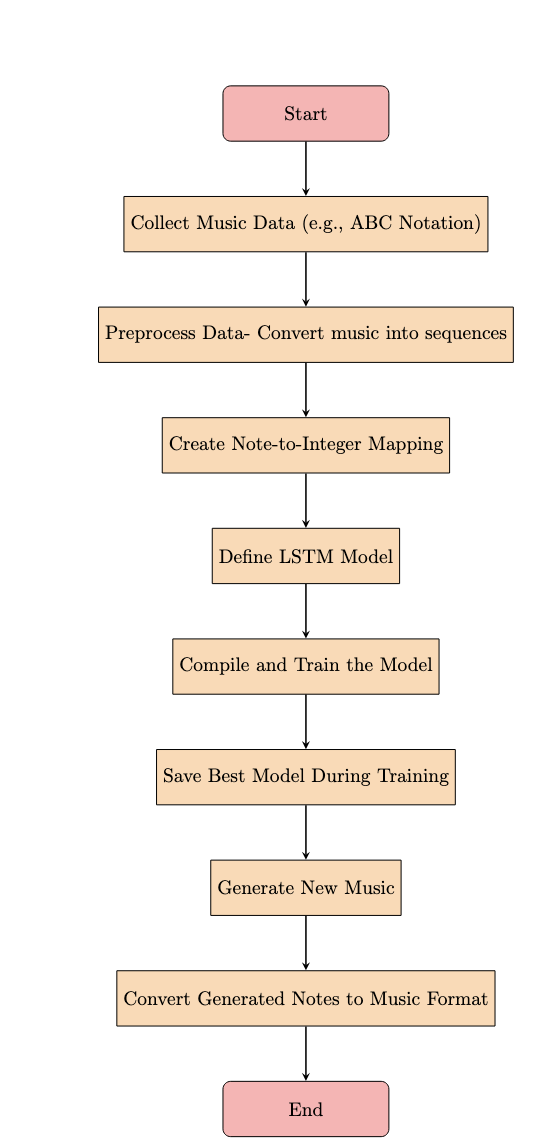
This is the Flow!!
Dropout is applied after each LSTM layer and Dense layer (with a dropout rate of 0.3). This helps reduce overfitting by randomly setting a fraction of input units to zero during training.
TDense(256): This fully connected layer has 256 units, processing the output from the LSTM layer before the final output layer.
Dense(n_vocab): The final output layer, where n_vocab represents the number of possible unique notes or categories. The output will have one unit per possible note. aarray using the function from Matplotlib & creat_model
that creates a lane detection model using the Sequential() function from Keras.
model = Sequential()
model.add(LSTM(256,input_shape=(100, 1), return_sequences=True))
model.add(Dropout((0.3))#dropout regularisation
model.add(LSTM(512,, return_sequences=True))
model.add(Dropout((0.3))#dropout regularisation
model.add(LSTM((256))#Third LSTM Layer
model.add(Dense((256))#Fully Connected layer
model.add(Dropout((0.3))#dropout
model.add(Dense((326))#Final Output Layer
model.add(Activation(("softmax"))#Activation
model.compile(loss='categorical_crossentropy',optimizer='rmsprop')Softmax Activation: After the final dense layer, a softmax activation function is applied to the output, which is typical for classification tasks. It converts the raw output scores into probabilities (for each note or category).
Loss Function: The model uses categorical_crossentropy which is appropriate for multi-class classification (e.g., predicting the next note in a music sequence).rmspropis used for training the model, which is a good choice for training RNN-based models (like LSTM).
model.compile optimizer='Adam,"loss='mean_squared_error'
history= model .fit_generator(datagen.flow( X_train, y_train=batch_size ="70" height="50" fill="blue"
steps_per_epoch=len (X_train)60/ batch_size
epochs=epochs, verbose=1,validation_data =(X_val,y_val ))
model.trainable=False
💡 sFor music generation, augment your training data by shifting sequences, transposing them, or adding
slight noise.This helps improve the model's robustness and generalization ability.
Cool, so here's our output Music genrated.
Flow of Work permalink
Data Collection:Describe how the data was collected or sourced.
Preprocessing: Explain how the sequences were extracted, how the notes (or values) were encoded as integers, and how the dataset was split into training and validation sets.
notes= ['C', 'D',
'E', 'F', 'G', 'A','B']# Sample data, replace with actual data
note_to_int= note: number for number, note,inenumerate=(notes)# Mapping notes to integers
n_vocab =len(note_to_ int)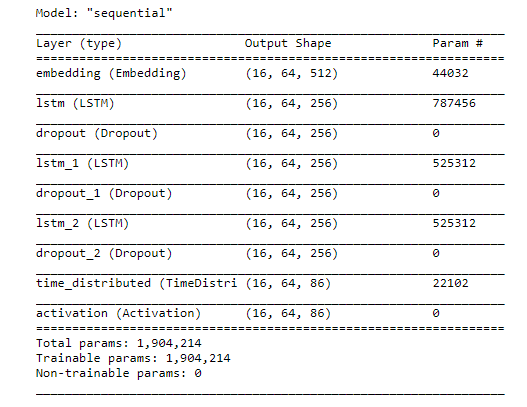
The model trained for 50 epochs with a batch size of 64. During training, the loss decreased steadily, and the model began generating coherent sequences after several epochs. If you are working with music, you might collect a dataset of MIDI files or a list of musical notes.This is a great article from medium if you want to dig into it a bit more.
For LSTM models, ensure that all input sequences have the same length. Use padding to make shorter sequences the same length as the longest sequence
from keras.preprocessing.sequence import.pad_sequences
padded_data =pad_sequences(int_data ,padding='post')
Split the data into input-output pairs for training. In sequence prediction, you create windows of sequences where each input sequence predicts the next value in the sequence.
One-hot encodethe output (e.g., if you're predicting categorical values like musical notes).
One-hot encoding creates binary vectors where each vector corresponds to a class..
Here's an example of the starting i did.
from keras. utilsimport to_categorical
plt y_encoded = to_categorical( y,y,num_classes=n_vocab)